
Victor Vasarely (1906-1977) – “Parmenide” – Quadro ad olio
Linked Data e Semantica: un approccio per la collaborazione
di Riccardo Grosso
Realizzare un’architettura che permetta la collaborazione tra la struttura Centrale e quella Locale è un obiettivo fondamentale. Ecco un'esperienza di creazione di un repository sulla parte PAL riutilizzando i risultati e le tecniche maturate a seguito del lavoro svolto sulla PAC.
Dal 1995 ho il pallino delle ontologie informatiche. Da allora ho scoperto un mondo che vuol dire soprattutto conoscenza, ma che è anche un'arte. Arte della conoscenza che deve diventare sempre più open.
Le prime forme di ontologie informatiche di cui mi sono occupato sono stati i modelli concettuali dei dati, e i dizionari dati.
Archetipi delle ontologie informatiche, che vediamo intorno a noi sempre di più nella moderna società della conoscenza, basata sui dati: open data, open knowledge, linked open data, big data, metadati.
Dal 1995 mi affascina la potenza matematica e astrattiva del data modeling concettuale con l’uso dei modelli entità relazione (oggi si parla di ontologie informatiche) e realizzo un data dictionary con ricerca like nei metadati, idea che riprenderò più avanti.
Grazie all’idea della ricerca like nei metadati, insieme a Carlo Batini metto a punto una metodologia e tools per fare knowledge extraction nei metadati usando ontologie della pubblica amministrazione centrale come "esche da pesca" nella ricerca concetti.
La mia idea è arrivare a collegare gli asset di un datacenter a partire dal server fisico, risalendo ai database implementati nei server, risalendo ancora alle entità concettuali della pubblica amministrazione. Inoltre il progetto del catalogo metadati, e l’uso di ontologie per correlare dati e metadati, si ripropone come idea applicabile ai linked open data.
L’obbiettivo è la descrizione delle scelte metodologiche e progettuali che hanno portato allo sviluppo di un tool atto alla creazione di repository di base dati.
L’ambito su cui si è operato è la Pubblica Amministrazione Locale (PAL). Il fine del lavoro è quello di studiare un repository di basi dati della Pubblica Amministrazione Centrale (PAC), creato anni addietro, per costruirne uno specifico per quella Locale sfruttando le analogie delle strutture amministrative.
Al fine di sviluppare il tool in una sua prima versione, si è analizzata la metodologia esistente ed è stata implementata seguendo delle euristiche. L’ottenimento di un simile prodotto permette l’automazione di un lavoro manuale intellettuale diminuendo drasticamente il tempo computazionale.
Un repository può essere definito come una collezione di schemi concettuali raggruppati secondo primitive di integrazione e astrazione che forniscono in output uno schema piramidale della conoscenza aziendale. Gli schemi concettuali utilizzano uno standard di rappresentazione fondato sul modello Entity Relationship, che permette di mostrare molto efficacemente le relazioni esistenti tra oggetti del sistema, rappresentando la realtà per mezzo di classi di oggetti del mondo reale, con l’aggiunta di relazioni ed attributi.
Il primo lavoro svolto per la costruzione di un repository della Pubblica Amministrazione iniziò una decina di anni fa; l’attività aveva come scopo l’analisi degli archivi dipartimentali della Pubblica Amministrazione Centrale al fine di creare una piramide concettuale che riuniva le varie fonti di conoscenza. Il contributo speso per la costruzione del repository PAC è stato molto salato in termini di risorse lavoro.
Oggi, allo scopo di realizzare un’architettura che permetta la collaborazione tra la struttura Centrale e quella Locale, si è deciso di creare un repository sulla parte PAL riutilizzando i risultati e le tecniche maturate dall’esperienza a seguito del lavoro svolto sulla PAC.
Nella nuova metodologia si è fatto uso di euristiche con lo scopo di diminuire drasticamente il tempo di completamento e ridurre al minimo il numero di risorse coinvolte nell’opera.
Una prima approssimazione operativa si fonda sul riutilizzo dei concetti presenti nella piramide concettuale della PAC, in modo tale da riutilizzare la stessa conoscenza per la riconcettualizzazione degli schemi logici della PAL, con un risparmio di tempo significativo rispetto al lavoro intrapreso dieci anni fa.
Come nel caso PAC, la metodologia di lavoro si compone di 2 fasi principali:
- Riconcettualizzazione degli schemi logici delle basi dati . La conoscenza fornita dal gestore della Pubblica Amministrazione Locale è sotto forma di schemi logici e poco manipolabili concettualmente; è necessaria quindi una operazione di reverse engineering che segua una metodologia specifica.
- Integrazione/Astrazione. Operazione di aggregazione e semplificazione di schemi concettuali per rappresentare la conoscenza ad un minor livello di dettaglio.
La fase di riconcettualizzazione segue una metodologia composta da cinque passi elementari, atti ognuno ad aggiungere una parte di conoscenza allo schema concettuale che incrementalmente si costruisce.
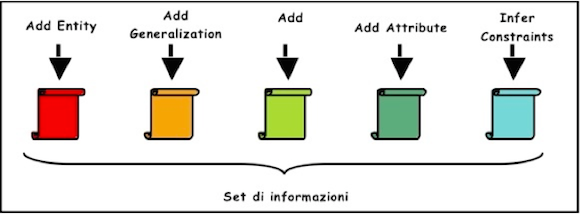
Allo scopo di realizzare nel più breve tempo possibile una versione del tool stabile e completa si è deciso di applicare delle euristiche alla metodologia originale sui dati PAL. Tali semplificazioni risiedono negli algoritmi applicati in ogni funzione, dunque non si è modificata la struttura metodologica delle operazioni ma soltanto alcuni aspetti che in futuro potranno essere facilmente modificati riscrivendo le funzioni interessate.
A tale scopo, si è preferito creare un semplice output testuale specifico per ogni funzione che ne contenga le informazioni raccolte. L’insieme di tali schemi prodotti nei passi per la riconcettualizzazione forma un set di informazioni indipendenti tra loro che possono essere analizzate singolarmente.
Data l’automazione della metodologia che si basa su approssimazioni, è necessaria una verifica tecnica di un esperto che ha lo scopo di correggere gli schemi concettuali prodotti e analizzare la struttura del repository creato alla fine del lavoro.
La creazione degli schemi sovrastanti differisce dalla metodologia originale PAL, in quanto troppo complessa da implementare in un ristretto periodo di tempo, e divergente dagli scopi prefissati di tale lavoro.
Nella fase di sviluppo si sono prodotti, in fase incrementale, i 5 passi per la riconcettualizzazione di uno schema logico di un database PAL e il passo unico per l’integrazione-astrazione.
Terminata tale fase di sviluppo delle funzioni base, è stato possibile progettare ed implementare funzioni di alto livello di più facile utilizzo, che richiamano le funzioni base in una corretta sequenza logica.
Il tool è stato così suddiviso in tre macroaree, abbinate a possibili funzioni utente:
- riconcettualizzazione di un database;
- integrazione-astrazione di schemi;
- creazione di un repository.
Come è facile notare, le aree crescono linearmente di complessità richiamando i concetti dell’area precedente.
A seguito dell’interesse suscitato dalla realizzazione del programma sono state pianificate delle operazioni di miglioramento con lo scopo di innalzare la qualità del prodotto finale.
Il perfezionamento si sviluppa su due strade parallele: la puntualità dei contenuti di uno schema concettuale e la migliore rappresentazione dello stesso.
Recentemente AgID inaugura il censimento delle basi dati della pubblica amministrazione. Un elenco di 12223 e oltre titoli di basi dati e applicazioni. Ma potenzialmente una miniera di informazioni per fare un serio riuso di conoscenza, se acquisissimo le strutture logiche dei database delle p.a. italiane.
Partendo dal catalogo AgID, ho estratto conoscenza da nomi e descrizioni di basi dati e applicativi, qui è riassunto il tutto.
Ho anche proposto a qualche università l'idea di questa tesi.
Ma i lavori più recenti, e forse i più interessanti, sono quelli che partono dall'idea di mappare le entità trattate dalle pubbliche amministrazioni basandosi sul catalogo AgID db e app.
Un caro amico, Marco Brancolini, mi ha aiutato a realizzare questo.
Da qui l'idea di rendere pubblico l'archivio IpaEntitiesgeo.
Ipaentitiesgeo è una elaborazione presa dal db delle PA al quale aggiungo le entità per ogni PA (queste le ottengo dal catalogo AgID facendo delle search like con i miei tools). Come si può vedere usando ipaentitiesgeo, oltre alle coordinate geografiche per ogni ipa, vi è una ultima colonna che si chiama entities, al cui interno vi sono una o più entità separate da un separatore.
E qui interviene l'aiuto di un altro grande amico, Francesco Piero Paolicelli, in arte Piersoft.
Ecco una applicazione da lui realizzata con Telegram, con la quale si può accedere ad alcuni metadati delle pubbliche amministrazioni e le entità che usano o trattano. Ecco il link al bot.
I prossimi passi:
1) produzione del file ipaentitiesgeo con tutte le P.A., oggi ha solo quelle che hanno almeno un match con la ricerca like per entità nei metadati db e app di AgID
2) merge di ipaentitiesgeo con i metadati AgID db e app
Voglio sottolineare, per i palati più sopraffini, che le entità che uso per le ricerche possono essere arricchite e/o sostituite da altre entità da parte di chi vorrà fornirle e condividerle.
Usare gerarchie di entità, e relazioni, per ricerche like nei metadati, è una semplice tassonomizzazione.
Non c'è la pretesa di arrivare in cima all'Everest delle ontologie modello DOLCE, ma un aiuto, una strada ferrata a cui aggrapparsi per arrivare meglio in cima.
Il prossimo passo potrà essere, una volta mappate le entità nelle P.A. grazie al catalogo AgID, affinare la mappatura ottenendo gli schemi delle basi dati dalle P.A.

